搜索到
61
篇与
龙流
的结果
-
 Vue实现点击列勾选或取消前面的复选框 示例说明<table> <thead> <tr> <th>姓名</th> <th>年龄</th> <th>手机号</th> </tr> </thead> <tbody> <tr v-for="c in tableData"> <td><input :id="c.id" v-model="checkItemIds" type="checkbox" :value="c.id"></td> <td><label :for="c.id">{{c.name}}</label></td> <td><label :for="c.id">{{c.age}}</label></td> <td><label :for="c.id">{{c.phone}}</label></td> </tr> </tbody> </table> <script> Vue app = new Vue({ /** ...省略具体Vue属性和方法函数; 渐进式Vue方案 */ }) </script>实现原理1、在<input>标签中使用id属性绑定c.id2、使用<label>标签:for="c.id"双向绑定id值,包裹插值属性值双向绑定在复选框选中多个数据项后,id值会以数组的形式存进checkItemIds数组中
Vue实现点击列勾选或取消前面的复选框 示例说明<table> <thead> <tr> <th>姓名</th> <th>年龄</th> <th>手机号</th> </tr> </thead> <tbody> <tr v-for="c in tableData"> <td><input :id="c.id" v-model="checkItemIds" type="checkbox" :value="c.id"></td> <td><label :for="c.id">{{c.name}}</label></td> <td><label :for="c.id">{{c.age}}</label></td> <td><label :for="c.id">{{c.phone}}</label></td> </tr> </tbody> </table> <script> Vue app = new Vue({ /** ...省略具体Vue属性和方法函数; 渐进式Vue方案 */ }) </script>实现原理1、在<input>标签中使用id属性绑定c.id2、使用<label>标签:for="c.id"双向绑定id值,包裹插值属性值双向绑定在复选框选中多个数据项后,id值会以数组的形式存进checkItemIds数组中 -
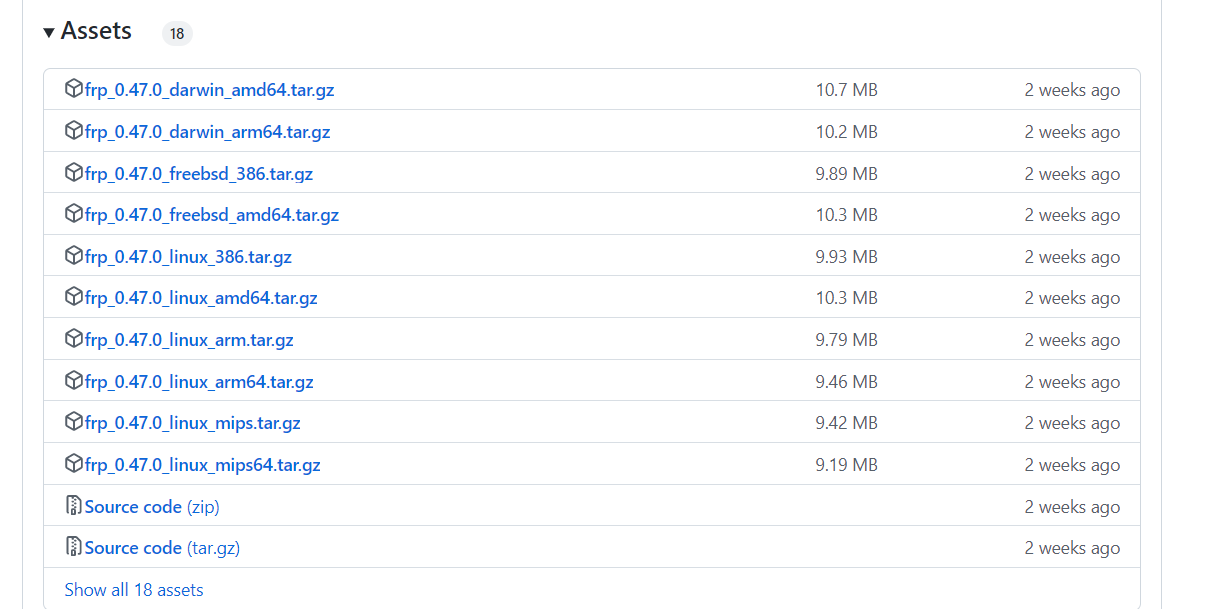
搭建自己的内网穿透服务 内网穿透:就是让外部的用户可以访问没有公网ip例如局域网内部的地址。缺点:就是你还是要有一个公网ip,在公网ip服务器上搭建映射服务,映射到目标地址!开始1、一台公网IP的服务器(示例:xx.bbb.xx.bbb)2、下载frp,我的系统是centos7,下载的是linux_amd64,如果想在电脑上实现就用windows,按需下载(githup地址:https://github.com/fatedier/frp/releases)3、将对应压缩包上传到服务器,然后解压tar -zxvf frp_0.47.0_linux_amd64.tar.gz4、服务器端配置,首先进入解压目录 cd frp_0.42.0_linux_amd64 ,然后编辑配置文件 vi frps.ini按i进行内容修改,修改内容如下,最后Esc键,输入:wq 回车即退出保存。[common] # 服务端口,这个一般不要改它 bind_port = 7000 # 设置仪表盘端口 dashboard_port = 7500 # 设置仪表盘访问的用户名密码 dashboard_user = admin dashboard_pwd = admin # frp支持 TCP、UDP、HTTP、HTTPS 等多种协议的穿透 # HTTP协议穿透只需要再增加一个vhost_http_port配置,这个端口号可随意配置服务器的闲置端口,这里使用8000 vhost_http_port = 80005、阿里云控制台安全组规则中开放7000、7500、8000端口6、使用以下指令启动frp服务端 ./frps -c ./frps.ini或使用nohup ./frps -c frps.ini >> frps.log 2>&1 &让程序在后台运行并将日志输出到指定文件比如frps.log7、浏览器查看部署情况 http://你的ip:7500服务端配置完成,开始客户端配置1、解压windows版压缩包到指定目录2、修改frpc.ini[common] server_addr = 服务器的公网IP server_port = 7000 [ssh] #这个名字可以随便改 type = tcp #通常tcp,udp按需修改 local_ip = 127.0.0.1 #一般不修改 local_port = 22 #外界连接本机的哪个端口 remote_port = 15000 #外界可以通过哪个端口访问进来 #外界通过 公网IP + remote_port ---访问---> local_ip + local_port #如:访问1.2.3.4:15000 实质访问 127.0.0.1:22 [web] type = http local_port = 8080 custom_domains = 公网IP或公网ip的解析域名3、在本地Windows找到安装目录,在上面的输入框中输入cmd,进入安装目录的命令行输入frpc.exe -c frpc.ini命令运行程序4、公网访问测试现在可以在公网通过公网IP和server_port访问本地web服务了
-
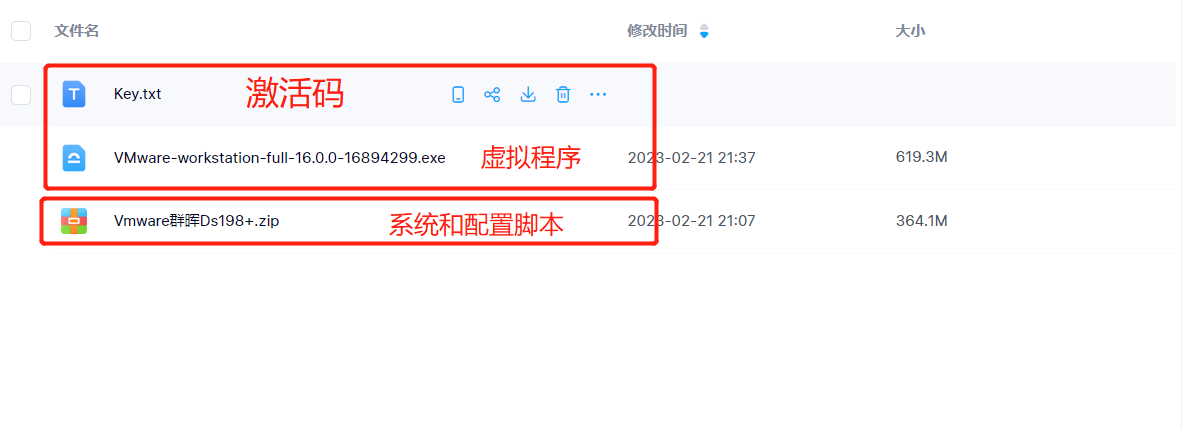
搭建黑群晖使用小白记录 准备工作安装VMware 16虚拟机,低版本虚拟机配置文件可能识别不了;安装文件链接: https://pan.baidu.com/s/16o3NGnU3ELLA8Q7DpdOl-g?pwd=3e4b 提取码: 3e4b安装过程虚拟机安装过程不在详列,基本上都是下一步;1、鼠标右键刚刚解压出来的虚拟机配置文件,打开方式选择【VMware虚拟机】。2、然后先别着急打开VMware虚拟机,先点击【编辑虚拟机设置】3、点击【添加】按钮4、点击【硬盘】,然后下一步5、在“磁盘类型”这里选择【SATA】, 继续下一步6、保持默认的【创建新虚拟机磁盘】,下一步7、选择【将虚拟磁盘储存为单个文件】,磁盘大小根据自己的实际需要填写,建议不低于20GB,然后下一步8、最后点击【完成】按钮9、回到VMware虚拟机设置,点击【网络适配器】,选择【桥接模式】,勾选下面的【复制物理网络连接状态】,然后点击【确定】保存10、然后看到虚拟机设备下面出现的和我们刚设置的一样的时候,就可以点击【开启此虚拟机】了。11、点击【我已复制该虚拟机】12、这里保持默认即可,等下我自动打开13、当出现这个界面的时候就说明VMware虚拟机已经成功的运行黑群晖NAS系统了14、打开浏览器,输入网址: https://finds.synology.com,如果没找到就多刷新几次,一般需要3分钟时间,就能看到出现类似于上图中的界面了。因为我之前安装过别的虚拟机黑群晖,在加上自己家里的黑群晖,所以上图中的排列很多,你首次安装所以你那边可能就一个。等到出现之后,选中它点击【连接】按钮。15、勾选【我已阅读并同意】,下一步16、继续17、出现这个界面就点击【安装】按钮18、然后点击【浏览】,选择我们下载好的“群晖DSM系统文件”,然后下一步19、勾选【我了解】,点击继续20、然后它就会自动安装群晖系统到我们的虚拟机中了。21、安装好以后就会提示自动重启,这个倒计时不用管它,一般3分钟内就可以重启成功22、重启成功之后就是这个界面,也就是自动安装内置套件。23、当你看到这个界面的时候,恭喜你!你基本已经成功了99%!直接点击【开始】,进行以后的设置24、开始创建账户。设备名称和管理员账户随意填写(不能是admin),然后设置一个密码(别设置简单了,首位字母大写),然后下一步25、勾选【当有可用.......手动安装】 ,下一步26、点击【跳过】,这个是一个官方提供的服务咱们黑群晖可以先玩玩,有能力支持正版。27、这里建议不勾选,直接点击【提交】按钮28、恭喜!!!现在基本上就算是稳了,配置一下硬盘安全策略。29、我们这里是使用的虚拟机,只分配了一个硬盘所以选择【Basic】方式,下一步。30、点击【开始】31、勾选硬盘 ,下一步32、点击【继续】33、勾选【跳过硬盘检查】,然后下一步34、点击【最大化 】,继续下一步35、保持默认(Btrfs),继续下一步36、点击【应用】37、点击【确定】38、欢迎来到群晖的世界!!!39、VMware虚拟机黑群晖7.0套件中心40、VMware虚拟机黑群晖7.0控制面板群晖NAS的玩法非常多,至于你要怎么玩,就看你要怎么折腾了!NAS玩家的必备技能,使用IPv6外网远程访问保姆教程万字带你从NAS小白变高端玩家
-
MySQL 8的SQL脚本为什么不能导入到MySQL 5中 原因:不可忽视的MySQL字符集 MySQL8.0的默认字符集编码为utf8mb4_0900_ai_ci而MySQL5.x中没有utf8mb4_0900_*的字符集这些字段每个意义,代表着什么含义:uft8mb4 表示用 UTF-8 编码方案,每个字符最多占4个字节。utf8mb3也是Unicode字符集的UTF-8编码,每个字符使用一到三个字节。(utf8: utf8mb3的别名)0900 就是Unicode 校对算法版本。(Unicode归类算法是用于比较符合Unicode标准要求的两个Unicode字符串的方法)。ai指的是口音不敏感。也就是说,排序时e,è,é,ê和ë之间没有区别,不区分重音。ci表示不区分大小写。排序时p和P之间没有区别。再了解一下一些场景下 utf8 和 utf8mb4 的问题点:utf8编码最多支持3字节的数据,而emoji表情符, 偏生字是4个字节的utf8无法存储的,致辞延伸出utf8mb4字符集解决这个问题。日常常用的字符集:utf8mb4_bin:将字符串每个字符用二进制数据编译存储,区分大小写,而且可以存二进制的内utf8mb4_general_ci:ci即case insensitive,不区分大小写。没有实现Unicode排序规则,在遇到某些特殊语言或字符集,排序结果可能不一致。但在绝大多数情况下,这些特殊字符的顺序并不需要那么精确。utf8mb4_unicode_ci:是基于标准的Unicode来排序和比较,能够在各种语言之间精确排序,Unicode排序规则为了能够处理特殊字符的情况,实现了略微复杂的排序算法。字符集配置mysql字符集如何设置,更改操作:1)my.cnf配置文件信息,建议初始化时就设置好。[mysqld]character-set-server = utf8mb4collation-server = utf8mb4_unicode_cicharacter-set-client-handshake = FALSE #此处是忽略客户端的字符集,使用服务器的设置2)init_connect=‘SET NAMES utf8mb4’ #服务器为每个连接的客户端执行的字符串,对于一些超级管理源就不生效的3)字符集变更,包含库,表,column的变更。都可以完全的拥有自己的字符集。##更改DATABASE ALTER DATABASE `db1` DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci ##更改TABLE ALTER TABLE `t1` DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci ##更改column字段 ALTER TABLE `t1` modify `name` varchar(80) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci COMMENT '昵称';4)日常字符集检查工作:SELECT b.SCHEMA_NAME, b.DEFAULT_CHARACTER_SET_NAME, b.DEFAULT_COLLATION_NAME ,a.TABLE_NAME, a.TABLE_COLLATION FROM information_schema.SCHEMATA b left join information_schema.TABLES a on b.SCHEMA_NAME =a. TABLE_SCHEMA WHERE b.SCHEMA_NAME not in ('information_schema' ,'mysql','performance_schema', 'sys') ORDER BY TABLE_SCHEMA,TABLE_NAME ;通过多方便设置,更改操作,检查。字符集不再是隐藏问题。字符集对于数据库的影响字符集对整个数据库影响面还是比较可观的。库更改 对于原先存在的表字段 都不影响 依次类推。所以数据库>表>字段 都可以单独设置字符集。常见问题1:有索引 没有走 因为进行了 字符集隐式转换常见问题2:在尾随空格方面不同字符串值(CHAR、VARCHAR和TEXT)的比较与其他排序规则在尾随空格方面不同。For example, ‘a’ and 'a ’ 作为不同的字符串比较,而不是相同的字符串。对于字符集排序来说,字符串末尾的空格也有对应的处理。注意:在选择使用utf8mb4_0900 字符集之后空格 就需要处理。常见问题3:对于数据的大小写敏感除了lower_case_table_names之外,怎样有效使用大小写字符集设置,采用ut8mb4_bin字符集 既可,查询和数据插入解决。常见问题4:表情符,偏生字常见错误代码:1366 Incorrect string value: ‘\xF0\x9F\x99\x82’ for column ‘name’ at row 2指定Utf8mb4字符集,再配合character-set-client-handshake属性图片备注:对于jdbc来说没有utf8mb4这样的字符集说法。不可忽视的MySQL字符集https://blog.51cto.com/u_15127623/2856333
-
-
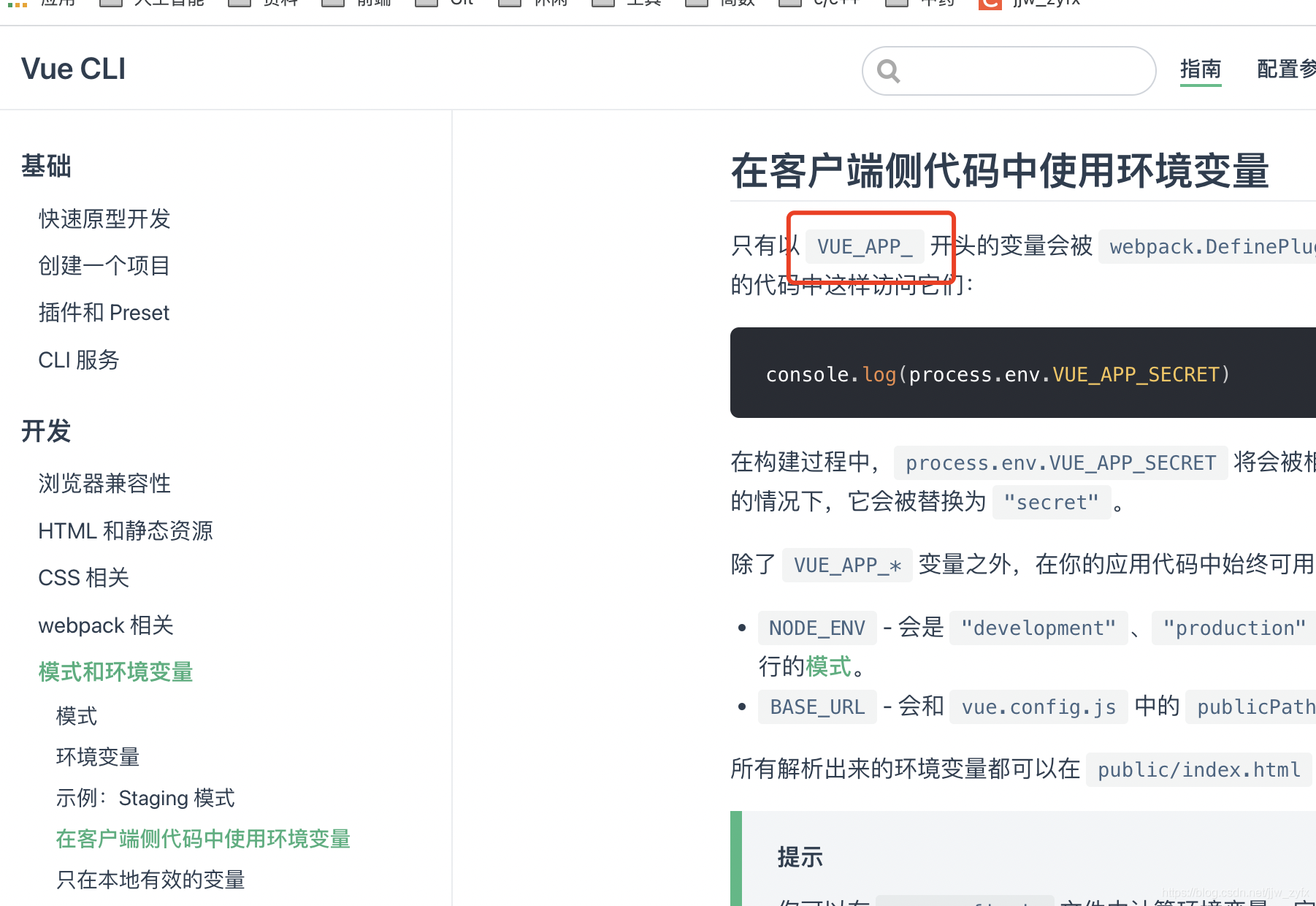
【VUE】process.env详解 process 是个全局变量使用的时候可以直接使用process.env 是 Node.js 中的一个环境对象。其中保存着系统的环境的变量信息。可使用 Node.js 命令行工具直接进行查看。模式的应用有了模式的概念,就可以根据不同的环境配置模式,就不用每次打包时都去更改 vue.config.js 文件了。比如在测试环境和生产环境, publicPath参数 (部署应用包时的基本 URL) 可能不同。遇到这种情况就可以在 vue.config.js 文件中,将 publicPath 参数设置为:publicPath: process.env.BASE_URL设置之后,再在各个 .env.[mode] 文件下对 BASE_URL 进行配置就行了,这样就避免了每次修改配置文件的尴尬。其他的配置也是同理。Tips: 即使不是生产环境,也可以将模式设置为 production ,这样可以获得 webpack 默认的打包优化。————————————————版权声明:本文为CSDN博主「Lucky@Dong」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。原文链接:https://blog.csdn.net/zzddada/article/details/122556869也就是说 只有是VUE_APP开头的才会被识别,其他的都不行
-
-
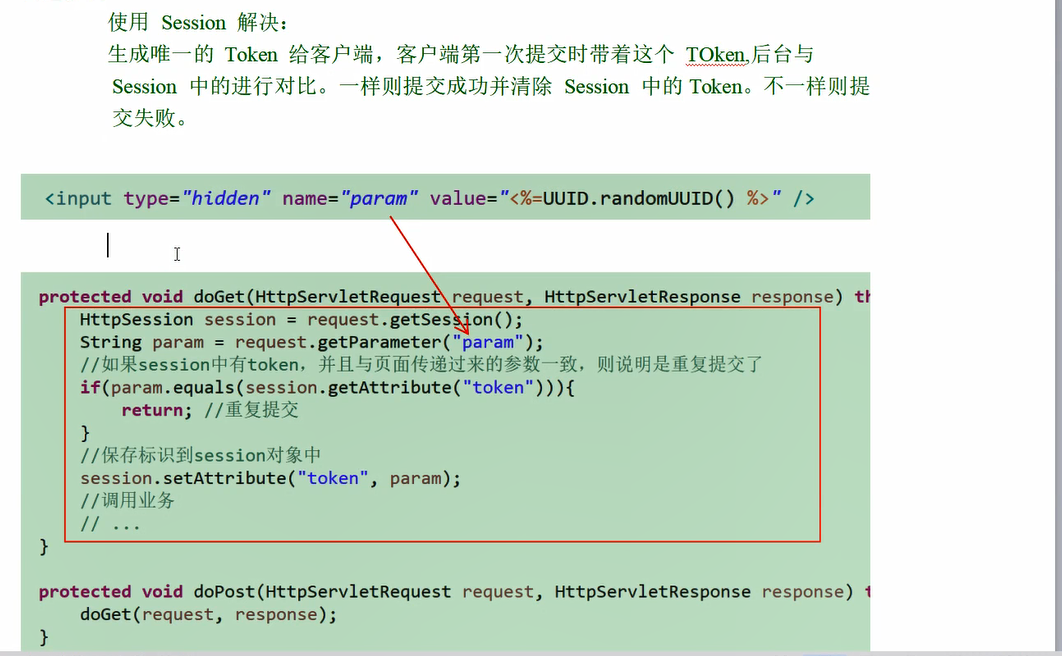
JavaWeb前端技术细节记录 1、关于ajax技术? ajax的优点有: 1、提高了性能和速度减少客户端和服务器之间的流量传输,同时减少了双方响应的时间,响应更快,因此提高了性能和速度。 2、交互性能好可以异步与后台服务器发送数据,并返回数据到前台 3、异步调用客户端浏览器在开始渲染之前避免等待所有数据到达 4、节省带宽基于Ajax的应用程序使用较少的服务器带宽,因为无需重新加载完整的页面。 5、使用XMLHttpRequestXMLHttpRequest在Ajax Web开发技术中起着重要作用。XMLHttpRequest是由Microsoft设计的特殊JavaScript对象。XMLHttpRequest对象调用作为异步HTTP请求到服务器以传输数据。它用于向非Ajax页面发出请求。 6、拥有开源JavaScript库 : JQuery,Prototype,Scriptaculous等。 7、AJAX通过HTTP协议进行通信。 ajax的缺点有: 1、不安全,因为所有的文件都是从客户端进行下载 2、网络延迟影响用户体验 3、禁用JavaScript的浏览器无法使用 4、由于安全限制,产生的跨域问题,相较传统经典web应用程序更复杂2、ajax内部的主要参数有哪些?① async:要求为boolean类型,异步为true(默认),同步为false。 ② url:要求为string类型的参数,发送请求的地址。 ③ type:要求为Stirng类型,请求方式post或get。 ④ data:要求为object或stirng类型,发送到服务器的数据。 ⑤ dataType:要求为String 类型,预期服务器返回的数据类型。 ⑥ beforeSend:要求为function类型的参数。例如添加自定义HTTP头 ⑦ timeout:要求为number类型,设置请求超时时间(毫秒)。 ⑧ cache:要求为boolean类型,默认为true,是否从浏览器缓存中加载信息。 3、cookie和session关系,原理cookie是存储在客户端的, session是存储在服务的的,cookie相比session不安全些session原理: 客户端a访问服务器时,服务器生成进行session对象生成然后保存在服务器中,同时会产生一个sessionid返回给客户端cookie中。 session会话有声明周期,可以通过设置session属性,设置session过期时间或者是关闭浏览器结束一次会话session也会失效Jquery的常用选择器有哪些?首先,Jquery选择器主要分为基本选择器,层级选择器,过滤选择器和表单选择器具体的: 基本选择器:具体示例见手册文档或百度 层级选择器: 过滤选择器: 表单选择器:
-
西方金融资本主义危机面临内爆风险,中国如何发展?未来转型方向 现在全球危机的真实背景是以美国为首的西方国家高负债的同时,高通胀走不下去了。那即将发生热战,而热战可能发生的地点就是这个世界上最大债权国日本和中国。只要把中国和日本的债权打掉,西方帝国主义国家的这些债务就会大幅的减少。那我们在这个不断的做逆周期调节的时候。现在提出的跨周期。跨周期指什么呢?我们跨越了资本主义金融阶段的这个阶段性的危机,我们要跨过这个阶段,直接进入到生态文明作为主导产业的新的阶段。 因此这个国家正在做重大战略调整,把新的理念树立起来,叫以人民为中心,以两山为手段。 那推进的是生态化改成资本主义,自产业资本以来不断发生危机的那个周期,所以我们要跨过这个周期的新的重大战略调整,这个战重大战略调整呢,我们认为对人类文明是有一定的引领作用,所以才说中华民族文明传承他伟大复兴,首先取决于在全球化的这场解体的大危机之中能不能维持住。以目前的这种大规模向农村投入,形成实体资产总量不断增加,这种做法维持的住目前国内的产业资本不至于崩解,但是目标不是这,这是短期(目标),你维持得住你的产业不至于垮掉,就维持住就业了。就不至于发生社会动乱了。接着要干嘛?要向生态化转型,不能再这样,就是完全靠着大进大出,在沿海地区布局了一批低端产业,然后为西方生产去支撑他的金融资本的扩张,过去的那个发展方式实在是不能再继续了,经过这一轮大危机,我想,呃,我们20年前就一直在这样,呃,试图警醒大家,呃,不是被我们惊醒的。被西方自己的大危机不断的爆发而警醒的,所以现在中国社会的大多数人都已经知道了,我们不能再像美国做这种双重攻击,来维持它的金融资本主义的续命。我们一定要转型,所以在这些事情上呢,我觉得在中国出现了一个新的现象,那些大企业家们啊,无论是大房地产商还是it商,他们手里拿的都是农产品,大资本急于要下乡,在经济危机的压力之下,过剩资本下乡已经成为一个必然趋势,那我们怎么才能维持的住弱势群体,特别是农民?他们的利益怎么保护,那我们看到也有一批中产阶级白领。他们也在下乡,但这些人下乡的要求的和大资本下乡要求圈占资源的目的是不同的,当然也包括很多在城市生存困难的这些房奴们,现在也放弃了在城市努力,选择下乡,所以现在呢,中国正在出现一次新的城乡融合的发展结构,这点呢,我们又是走在前面了,我们当时就在发动农民,发动群众,让他们形成组织。提高他们维护自己的资源权益,对外部资本做谈判的能力,提高他们的谈判能力就意味着保护他们的权利。类似像这样的事情,不仅是农民做,我们还要发动市民,所以我们现在说城乡融合,市民下乡,与农民联合共同创业,共同维护权益,走向绿色发展,这应该是我们推动生态文明建设的重要的内涵。那为此呢,我们也提出了。理论的归纳要从农业1.0到农业4.0,在农村中推进的所谓组织化,我们是根据生态资源环境条件来安排的。这点呢,我希望大家理解,往往一个山系,他的那个山的分水岭,就是现县、市这级的地缘边界。而一个山系的分水岭下面的这个山脉,这个沟系,往往就是一个乡镇,一个乡镇有多少个行政村分布在这条沟系里儿,小流域往往就是一个村。所以我们现在做的呢,就是如果在山区,目前我们的这个人口总量、资源总量、经济总量不够,那就以乡为单位来组建股份经济合作社的联合总社,所以这里边就给出了一个如何从农户到村社,再到乡社,最终呢在县域内形成集体经济的联合总社,这是一个在县里边儿开展工作的结构图。那我们最终要实现的是以县为单位的生态资源综合开发,让产业留在县域,让农民分享县域产业的收益的这样一个设计,我们把它叫做三级市场。制度创新先要在农村村内,由农民他们了解当地的资源情况来完成,对村域的资源性资产的定价,形成他们的资产本底。在和地方政府投资结合在一起,变成可以对接外部投资人和外部企业的工商注册的企业法人,但这叫做社会企业。我们用社会企业作为一个微观基础来对接外部投资人,因为合作社经济外部投资人所占的资产份额不超过20%,所以这仍然是农民群体自组织,自主发展的社会企业。然后再进一步,这个就是县域的融资平台。目前在中国国内有很多这方面的经验呢,客观上是因为什么呢?是因为中国在金融资本与美国竞争的过程中,美国的资本流入中国,中国是不开放人民币自由兑换的,所以他一定要对冲变成人民币,所以这个过程中间,人民币的这个货币总量也在大规模的上升,那就出现了客观上的金融过剩,当房地产不景气了,房地产总量过剩了,资金就不能进房地产了,那他进哪儿呢?所以我们现在正好是把过剩的资金拿来用于我们的三级市场建设,过去大量的资源性资产不得交易,不得开发,过去在资金短缺的时候,资本是不下乡的,那现在他过剩了,正好可以被我们打造的县域融资平台借用过来,成为地方的生态资源开发的金融工具,所以怎么把金融这个资本作为一个要素来使用,要靠我们做出的制度设计。目前的这个制度设计正在各地开展试点,一旦我们要是有经验了,我们会再向大家做汇报。总之呢,今天的这个时间有限,只能这样非常粗线条的把现在全球危机的真实背景是以美国为首的西方国家高负债的同时高通胀走不下去了,那即将发生热战,而热战可能发生的地点就是这个世界上最大债权国日本和中国。只要把中国和日本的债权打掉,西方帝国主义的国家的这些债务就会大幅的减少。当这个新冠疫情刚一爆发,美国的政客们急于甩锅,非得说这是中国搞的。要把它叫做中国病毒,然后接着提出,就是要扣掉中国在美国的国债市场的投资,大约是1万多亿美元,作为对美国的补偿,就赖债的说法早就提出了,2020年早就提出,但是接着美国也爆发了新冠疫情,那这个甩锅不成了,那就进一步甩其他的锅,当这个其他的锅甩的也困难的时候,干脆就建立了所谓的民主国家的什么贸一体化,什么关税同盟等等,这些东西其实无外乎就是赖战联盟。就是现在战争的导火索,我们把这个道理讲清楚,接着回过头来看,对中国来说,我们应该怎么着?我们应该转型,我们不在同一个层次上跟西方帝国主义国家做竞争,我们转向生态文明。我们把我们的金融力量,产业力量用在生态化转型上,我们把这叫做跨周期调节好了,我今天给大家的汇报就说到这儿啊,肯定有很多错误啊,这个是个讨论性的提纲啊,说错了或者大家不同意呢,欢迎批评,谢谢。
-