搜索到
1
篇与
序列化
的结果
-
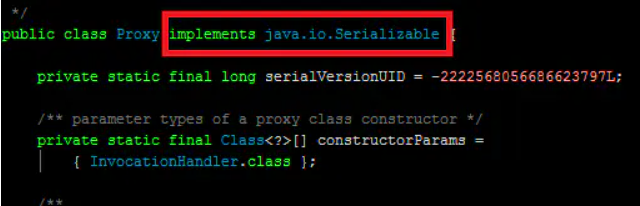
 序列化与反序列化 把对象转换为字节序列的过程称为对象的序列化。把字节序列恢复为对象的过程称为对象的反序列化。对象的序列化主要有两种用途:把对象的字节序列永久地保存到硬盘上,通常存放在一个文件中;在网络上传送对象的字节序列。使用场景 在很多应用中,需要对某些对象进行序列化,让它们离开内存空间,入住物理硬盘,以便长期保存。比如最常见的是Web服务器中的Session对象,当有 10万用户并发访问,就有可能出现10万个Session对象,内存可能吃不消,于是Web容器就会把一些session先序列化到硬盘中,等要用了,再把保存在硬盘中的对象还原到内存中。 当两个进程在进行远程通信时,当我们需要使用的对象很复杂或者需要很长时间去构造,这时就会引入使用代理模式(Proxy)。例如:如果构建一个对象很耗费时间和计算机资源,代理模式(Proxy)允许我们控制这种情况,直到我们需要使用实际的对象。一个代理(Proxy)通常包含有和将要使用的对象同样的方法,一旦开始使用这个对象,这些方法将通过代理(Proxy)传递给实际的对象。解读:在微服务化盛行的今天,很多复杂的对象构造起来比较耗时,为了节省开支,某些公司将这部分复杂的对象先圈起来,写成服务起在远端B,并在调用端A端以代理(Proxy)的形式提供对服务的访问,这期间从B到A远程调的过程形成了Java对象序列化和反序列化的相关操作!深入理解JDK提供了个代理类:import java.lang.reflect.Proxy; 来看一下Proxy的实现Proxy在JDK中实现了Serializable(序列化)接口,但是代理是怎么实现将服务端的对象运行到客户端上的呢?第一步:远端JVM(服务端)对“对象”使用序列化后通过网络传输的方式将对象的字节序列发送到本地(客户端)第二步:本地代理(Proxy)将接收到的字节序列再通过反序列化恢复成”对象”,并使这个"对象"活在本地的JVM中;从上面两步来看,序列化的过程是在服务端做的;反序列化是在客户端做的;那么有个问题来了,从源码上看,Proxy(本地)实现了反序列化,服务端在哪里实现了序列化呢?带着这个问题,继续查看了服务端所有的代码,发现有的公司直接在实体上Serialize,有的则在类上加@Serializable注解利用切面实现,但终究实现了序列化;JDK类库中的序列化APIjava.io.ObjectOutputStream代表对象输出流,它的writeObject(Object obj)方法可对参数指定的obj对象进行序列化,把得到的字节序列写到一个目标输出流中。java.io.ObjectInputStream代表对象输入流,它的readObject()方法从一个源输入流中读取字节序列,再把它们反序列化为一个对象,并将其返回。 只有实现了Serializable和Externalizable接口的类的对象才能被序列化。Externalizable接口继承自 Serializable接口,实现Externalizable接口的类完全由自身来控制序列化的行为,而仅实现Serializable接口的类可以 采用默认的序列化方式 。对象序列化/** * @ClassName: Student * @author: WeiLong * @description 学生类 */ public class Student implements Serializable{ private String name; private int age; public Student(String name, int age) { this.name = name; this.age = age; } public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } }注意:需要序列化的类需要实现Serializable接口,获取上述其他方法,否则会出现NotSerializableException //实现序列化 public static void SerializeStudent() throws IOException{ //1、序列化流 ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("java基础\\oos.txt")); //2、创建student对象 Student student = new Student("张三",18); oos.writeObject(student); System.out.println("Student对象序列化成功"); //3、关闭流 oos.close(); }对象反序列化 public static Student DeserializeStudent() throws IOException, ClassNotFoundException { ObjectInputStream ois = new ObjectInputStream(new FileInputStream("java基础\\oos.txt")); Student student = (Student) ois.readObject(); System.out.println("Student对象反序列化完成"); ois.close(); return student; }serialVersionUID的作用序列化对象未加serialVersionUID时,反序列化异常serialVersionUID: 字面意思上是序列化的版本号,凡是实现Serializable接口的类都有一个表示序列化版本标识符的静态变量 序列化版本ID的真实用途:当实体中增加属性后,文件流中的class和classpath中的class,也就是修改过后的class,不兼容了,处于安全机制考虑,程序抛出了错误,并且拒绝载入。那么如果我们真的有需求要在序列化后添加一个字段或者方法呢?应该怎么办?那就是自己去指定serialVersionUID。在例子中,如果没有指定Person类的serialVersionUID的,那么java编译器会自动给这个class进行一个摘要算法,类似于指纹算法,只要这个文件多一个空格,得到的UID就会截然不同的,可以保证在这么多类中,这个编号是唯一的。所以,添加了一个字段后,由于没有显指定serialVersionUID,编译器又为我们生成了一个UID,当然和前面保存在文件中的那个不会一样了,于是就出现了2个序列化版本号不一致的错误。因此,只要我们自己指定了serialVersionUID,就可以在序列化后,去添加一个字段,或者方法,而不会影响到后期的还原,还原后的对象照样可以使用,而且还多了方法或者属性可以用。可以说serialVersionUID是序列化和反序列化之间彼此认识的唯一信物。IDEA设置自动生成serialVersionUID
序列化与反序列化 把对象转换为字节序列的过程称为对象的序列化。把字节序列恢复为对象的过程称为对象的反序列化。对象的序列化主要有两种用途:把对象的字节序列永久地保存到硬盘上,通常存放在一个文件中;在网络上传送对象的字节序列。使用场景 在很多应用中,需要对某些对象进行序列化,让它们离开内存空间,入住物理硬盘,以便长期保存。比如最常见的是Web服务器中的Session对象,当有 10万用户并发访问,就有可能出现10万个Session对象,内存可能吃不消,于是Web容器就会把一些session先序列化到硬盘中,等要用了,再把保存在硬盘中的对象还原到内存中。 当两个进程在进行远程通信时,当我们需要使用的对象很复杂或者需要很长时间去构造,这时就会引入使用代理模式(Proxy)。例如:如果构建一个对象很耗费时间和计算机资源,代理模式(Proxy)允许我们控制这种情况,直到我们需要使用实际的对象。一个代理(Proxy)通常包含有和将要使用的对象同样的方法,一旦开始使用这个对象,这些方法将通过代理(Proxy)传递给实际的对象。解读:在微服务化盛行的今天,很多复杂的对象构造起来比较耗时,为了节省开支,某些公司将这部分复杂的对象先圈起来,写成服务起在远端B,并在调用端A端以代理(Proxy)的形式提供对服务的访问,这期间从B到A远程调的过程形成了Java对象序列化和反序列化的相关操作!深入理解JDK提供了个代理类:import java.lang.reflect.Proxy; 来看一下Proxy的实现Proxy在JDK中实现了Serializable(序列化)接口,但是代理是怎么实现将服务端的对象运行到客户端上的呢?第一步:远端JVM(服务端)对“对象”使用序列化后通过网络传输的方式将对象的字节序列发送到本地(客户端)第二步:本地代理(Proxy)将接收到的字节序列再通过反序列化恢复成”对象”,并使这个"对象"活在本地的JVM中;从上面两步来看,序列化的过程是在服务端做的;反序列化是在客户端做的;那么有个问题来了,从源码上看,Proxy(本地)实现了反序列化,服务端在哪里实现了序列化呢?带着这个问题,继续查看了服务端所有的代码,发现有的公司直接在实体上Serialize,有的则在类上加@Serializable注解利用切面实现,但终究实现了序列化;JDK类库中的序列化APIjava.io.ObjectOutputStream代表对象输出流,它的writeObject(Object obj)方法可对参数指定的obj对象进行序列化,把得到的字节序列写到一个目标输出流中。java.io.ObjectInputStream代表对象输入流,它的readObject()方法从一个源输入流中读取字节序列,再把它们反序列化为一个对象,并将其返回。 只有实现了Serializable和Externalizable接口的类的对象才能被序列化。Externalizable接口继承自 Serializable接口,实现Externalizable接口的类完全由自身来控制序列化的行为,而仅实现Serializable接口的类可以 采用默认的序列化方式 。对象序列化/** * @ClassName: Student * @author: WeiLong * @description 学生类 */ public class Student implements Serializable{ private String name; private int age; public Student(String name, int age) { this.name = name; this.age = age; } public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } }注意:需要序列化的类需要实现Serializable接口,获取上述其他方法,否则会出现NotSerializableException //实现序列化 public static void SerializeStudent() throws IOException{ //1、序列化流 ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("java基础\\oos.txt")); //2、创建student对象 Student student = new Student("张三",18); oos.writeObject(student); System.out.println("Student对象序列化成功"); //3、关闭流 oos.close(); }对象反序列化 public static Student DeserializeStudent() throws IOException, ClassNotFoundException { ObjectInputStream ois = new ObjectInputStream(new FileInputStream("java基础\\oos.txt")); Student student = (Student) ois.readObject(); System.out.println("Student对象反序列化完成"); ois.close(); return student; }serialVersionUID的作用序列化对象未加serialVersionUID时,反序列化异常serialVersionUID: 字面意思上是序列化的版本号,凡是实现Serializable接口的类都有一个表示序列化版本标识符的静态变量 序列化版本ID的真实用途:当实体中增加属性后,文件流中的class和classpath中的class,也就是修改过后的class,不兼容了,处于安全机制考虑,程序抛出了错误,并且拒绝载入。那么如果我们真的有需求要在序列化后添加一个字段或者方法呢?应该怎么办?那就是自己去指定serialVersionUID。在例子中,如果没有指定Person类的serialVersionUID的,那么java编译器会自动给这个class进行一个摘要算法,类似于指纹算法,只要这个文件多一个空格,得到的UID就会截然不同的,可以保证在这么多类中,这个编号是唯一的。所以,添加了一个字段后,由于没有显指定serialVersionUID,编译器又为我们生成了一个UID,当然和前面保存在文件中的那个不会一样了,于是就出现了2个序列化版本号不一致的错误。因此,只要我们自己指定了serialVersionUID,就可以在序列化后,去添加一个字段,或者方法,而不会影响到后期的还原,还原后的对象照样可以使用,而且还多了方法或者属性可以用。可以说serialVersionUID是序列化和反序列化之间彼此认识的唯一信物。IDEA设置自动生成serialVersionUID