搜索到
61
篇与
龙流
的结果
-
 '搬砖’搜索比较多的操作 SQL Server 设置主键自增长:新增时:CREATE TABLE [dbo].[rescue_material_configure] ( [id] int IDENTITY(1,1) NOT NULL, [category_id] int NOT NULL, [material_name] varchar(100) COLLATE Chinese_PRC_CI_AS NULL, [base] varchar(100) COLLATE Chinese_PRC_CI_AS NULL, [operate_date] datetime NOT NULL )修改表时:ALTER TABLE [dbo].[nurse_impower_type_content] DROP COLUMN id; ALTER TABLE [dbo].[nurse_impower_type_content] ADD id BIGINT Identity(1,1) NOT NULL;SQL Server增加字段注释表注释EXEC sys.sp_addextendedproperty @name=N'MS_Description', @value=N'表注释' , @level0type=N'SCHEMA',@level0name=N'dbo', @level1type=N'TABLE',@level1name=表名'增加字段注释execute sp_addextendedproperty 'MS_Description','字段注释','user','dbo','table','表名','column','字段名';SQL Server 各种时间日期查询链接查询昨天日期:select convert(char,dateadd(DD,-1,getdate()),111) //111是样式号,(100-114) 查询半年前的现在日期时间:select DATEADD(MM,-6,GETDATE()) 查询一个月前当前的日期时间:select DATEADD(MM,-1,GETDATE())
'搬砖’搜索比较多的操作 SQL Server 设置主键自增长:新增时:CREATE TABLE [dbo].[rescue_material_configure] ( [id] int IDENTITY(1,1) NOT NULL, [category_id] int NOT NULL, [material_name] varchar(100) COLLATE Chinese_PRC_CI_AS NULL, [base] varchar(100) COLLATE Chinese_PRC_CI_AS NULL, [operate_date] datetime NOT NULL )修改表时:ALTER TABLE [dbo].[nurse_impower_type_content] DROP COLUMN id; ALTER TABLE [dbo].[nurse_impower_type_content] ADD id BIGINT Identity(1,1) NOT NULL;SQL Server增加字段注释表注释EXEC sys.sp_addextendedproperty @name=N'MS_Description', @value=N'表注释' , @level0type=N'SCHEMA',@level0name=N'dbo', @level1type=N'TABLE',@level1name=表名'增加字段注释execute sp_addextendedproperty 'MS_Description','字段注释','user','dbo','table','表名','column','字段名';SQL Server 各种时间日期查询链接查询昨天日期:select convert(char,dateadd(DD,-1,getdate()),111) //111是样式号,(100-114) 查询半年前的现在日期时间:select DATEADD(MM,-6,GETDATE()) 查询一个月前当前的日期时间:select DATEADD(MM,-1,GETDATE()) -
java清理缓存实现 前台代码:<script> function CleanConfirm(){ var url="/devindex/function"; var data={f:'clearCache'}; $.ajax({ url: url, type: "post", dataType: "json", contentType: "application/json; charset=utf8", data: data, success: function(data) { if(data.success){ layerInfo(data.msg); }else{ layerInfo(data.msg); } } }); } </script>后台代码:@ResponseBody @RequestMapping({"/function"}) public Map function(String p_dm, @RequestParam Map<String, Object> paramMap, Model model, HttpServletRequest request, HttpServletResponse response) { if ("clearCache".equals(paramMap.get("f"))) { CommonCacheManager commonCacheManager = CommonCacheManager.getCommonCacheManager(); String cacheName = CACHENAME.COMMONAPICONFIG.name(); List<PFunctionsubEntity> pFunctionsubEntities = this.pFunctionSubService.GetOneDataByDm(p_dm); for(int i = 0; i < pFunctionsubEntities.size(); ++i) { PFunctionsubEntity pFunctionsubEntity = (PFunctionsubEntity)pFunctionsubEntities.get(i); commonCacheManager.removeCacheValue(cacheName, pFunctionsubEntity.getId()); commonCacheManager.removeCacheValue(cacheName, pFunctionsubEntity.getDm()); commonCacheManager.removeCacheValue(cacheName, pFunctionsubEntity.getMainid() + pFunctionsubEntity.getDm()); commonCacheManager.removeCacheValue(cacheName, pFunctionsubEntity.getId() + PFunctiontjoptEntity.class.toString()); commonCacheManager.clearCache(pFunctionsubEntity.getDm()); } if (StringUtil.isEmptyOrLength0(p_dm)) { commonCacheManager.clearCache(cacheName); commonCacheManager.clearCache((String)null); } Map resMap = new HashMap(); resMap.put("success", "true"); resMap.put("msg", "clearCache:" + (StringUtil.isEmptyOrLength0(p_dm) ? "all" : p_dm)); return resMap; } }
-
MyBatis入门到"入坟" mybatis它内部封装了jdbc,简化了原始持久层操作每次都要去处理加载驱动、创建连接、创建statement等繁杂的过程;上面这些操作,JDBCTemplate工具类也实现了,为什么JDBCTemplate不叫框架,而是工具类呢?原因是工具类只是对操作的一些封装,对于更多的细节它并没有去处理和提供解决方案。定制化SQL、存储过程、高级映射相较jdbc,SQL代码夹杂在Java代码中耦合度高不易维护相较Hibernate和JPA 自动生成SQL,不容易做特殊优化 反射太多,导致数据库性能下降mybatis的简单搭建打开idea创建一个空的maven项目,导入mybatis和数据库MySQL的maven依赖配置mybatis的配置文件(该配置文件名固定,以便项目启动是能识别找到该配置文件)<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN" "http://mybatis.org/dtd/mybatis-3-config.dtd"> <!-- mybatis的主配置文件 --> <configuration> <!-- 配置环境 --> <environments default="mysql"> <!-- 配置mysql的环境--> <environment id="mysql"> <!-- 配置事务的类型--> <transactionManager type="JDBC"></transactionManager> <!-- 配置数据源(连接池) --> <dataSource type="POOLED"> <!-- 配置连接数据库的4个基本信息 --> <property name="driver" value="com.mysql.jdbc.Driver"/> <property name="url" value="jdbc:mysql://localhost:3306/eesy_mybatis"/> <property name="username" value="root"/> <property name="password" value="1234"/> </dataSource> </environment> </environments> <!-- 指定映射配置文件的位置,映射配置文件指的是每个dao独立的配置文件 --> <mappers> <mapper resource="com/lwlong/dao/IUserDao.xml"/> </mappers> </configuration>顺便配置一下日志# Set root category priority to INFO and its only appender to CONSOLE. #log4j.rootCategory=INFO, CONSOLE debug info warn error fatal log4j.rootCategory=debug, CONSOLE, LOGFILE # Set the enterprise logger category to FATAL and its only appender to CONSOLE. log4j.logger.org.apache.axis.enterprise=FATAL, CONSOLE # CONSOLE is set to be a ConsoleAppender using a PatternLayout. log4j.appender.CONSOLE=org.apache.log4j.ConsoleAppender log4j.appender.CONSOLE.layout=org.apache.log4j.PatternLayout log4j.appender.CONSOLE.layout.ConversionPattern=%d{ISO8601} %-6r [%15.15t] %-5p %30.30c %x - %m\n # LOGFILE is set to be a File appender using a PatternLayout. log4j.appender.LOGFILE=org.apache.log4j.FileAppender log4j.appender.LOGFILE.File=d:\axis.log log4j.appender.LOGFILE.Append=true log4j.appender.LOGFILE.layout=org.apache.log4j.PatternLayout log4j.appender.LOGFILE.layout.ConversionPattern=%d{ISO8601} %-6r [%15.15t] %-5p %30.30c %x - %m\n创建映射文件mapper<?xml version="1.0" encodeing="UTF-8"?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"> <mapper namespace="com.lwlong.dao.IUserDao"> <!--查询所有用户--> <select id="findAll" resultType="com.lwlong.entity.User"> select * from user </select> </mapper>MyBatis的使用案例public static void main(String[] args)throws Exception { //1.读取配置文件 InputStream is = Resource.getResourceAsStream("SqlMapConfig.xml"); //2.创建SqlSessionFactory工厂 SqlSessionFactoryBuilder builder = new SqlSessionFactoryBuilder(); SqlSessionFactory factory = builder.build(is); //3.使用工厂生产SqlSession对象 SqlSession sqlSession = factory.openSession(); //4.使用SqlSession创建Dao(Mapper)接口的代理对象 IUserDao userDao = sqlSession.getMapper(IUserDao.class); //5.使用代理对象执行方法 List<User> users = userDao.findAll(); for(User user : users) { System.out.println(user); } //6.释放资源 sqlSession.close(); is.close(); }MyBatis细节处理解决方案MyBatis获取参数的几种方式1、通过#{}方式,原理是占位符的形式,可以防止SQL注入,替换的参数默认使用''包围2、通过${}方式,原理字符串拼接形式,存在SQL注入风险,传入的参数是什么就直接替换到SQL语句中3、Mapper的代理实现类,mapper接口方法的参数,底层对传入的参数是以Map的形式封装,默认有键为parma1,parma2 ...;在mapper.xml文件中sql的#{}、${}通过属性名获取,①使用java对象传递,对象的属性;②使用多个参数,mapper接口中参数设置@Param注解value值;③通过位置形式获取;④通过map通过${}方式,动态替换表名在标签中设置useGeneratedKeys="true"开启获取自增的主键,seyProperty="对象属性名"设置回写到对象属性中全局配置处理字段名和属性名不一致的情况在mybatis-config.xml配置文件中添加如下配置<settings> <!--将下划线映射为驼峰-> <setting name="mapUnderscoreTocamelcase" value="true"/> </settings>使用resultMap处理属性名与字段名不一致的情况在Mapper.xml映射SQL字段,使用标签,设置<resultMap id="empResultMap" type="com.xxx.Emp"><!--如果配置了mybatis全局别名配置,可以直接写默认简称别名--> <result property="empId" column="emp_id" jdbcType="int"/> <result property="empName" column="emp_name" jdbcType="String"/> <result property="age" column="age" jdbcType="int"/> </resultMap>也用来处理封装级联对象属性:关联查询中如员工信息关联部门信息,分别封装在对应的实体类中使用association来处理封装级联对象属性<association property="dept" javaType="Dept"> <id column="dept_id" property="deptId"></id> <result column="dept_name" property="deptName"></result> </ association> > MyBatis处理多对一的映射关系查询,使用分步的查询方式;缺点:写的查询语句多;优点:可以延迟加载 > 必须在全局配置文件中设置全局配置信息 > lazyLoadingEnabled:延迟加载的全局开关。当开启时,所有关联对象都会延迟加载 > aggressiveLazyLoading:当开启时,任何方法的调用都会加载该对象的所有属性。否则,每个属性会按需加载 > 此时就可以实现按需加载,获取的数据是什么,就只会执行相应的sql。此时可通过association和collection中的fetchType属性设置当前的分步查询是否使用延迟加载, fetchType="lazy(延迟加载)|eager(立即加载)"mybatis动态SQLMybatis框架的动态SQL技术是一种根据特定条件动态拼装SQL语句的功能,它存在的意义是为了解决拼接sQL语句字符串时的痛点问题。I标签的使用:ifif标签可通过test属性的表达式进行判断,若表达式的结果为true,则标签中的内容会执行;反之标签中的内容不会执行<!--List<Emp> getEmpListByCondition(Emp emp);--> <select id="getEmpListByMoreT" resultType="Emp"> select * from t_emp where 1=1 <if test="ename != '' and ename != nu11"> and ename = #{ename} </if> <if test="age != '' and age != nu11"> and age = #{age} </if> <if test="sex != '' and sex != nu11"> and sex = #{sex} </if> </select>wherewhere标签,可以自动生成where关键字,可以自动去除条件字段前的and关键字,不能去除条件字段后的and的关键字;trimtrim标签属性prefix、suffix:在标签中内容前面或后面添加指定内容prefixOverrides、suffixOverrides:在标签中内容前面或后面去掉指定内容<select id="getEmpListByMoreT" resultType="Emp"> select * from t_emp <trim prefix="where" suffixoverrides="and"> <if test="ename != '' and ename != nu11"> ename = #{ename} and </if> <if test="age != '' and age != nu11"> age = #{age} and </if> <if test="sex != '' and sex != nu11"> sex = #{sex} and </if> </trim> </select>choose、when、otherwise多条件判断组合标签,相当于java中的if...else if...elseforEach试用在批量添加、批量删除,非常常用的标签<!--void insertMoreEmp(@param ( " emps" ) List<Emp> emps);--> <insert id="insertMoreEmp"> insert into t_emp values <foreach collection="emps" item="emp" separator=","> (null,#{emp. empName} ,#{emp.age} ,#{emp.gender},null) </foreach> </insert> <!--void deleteMoreEmp(@param ( "empIds" ) Integer[] empIds);--> <delete id="deleteMoreEmp"> delete from t_emp where <foreach collection="empIds" item="empId" separator="or"> emp_id = #{empId} </foreach> </delete>sqlsql标签,定义一个sql片段,例如:在mybatis中建议不要写select * ...因为在执行时还是要去查找一遍具有的字段;也可以定义存储过程;<sql id="empcolumns"> emp_id,emp_name,age,gender,dept_id </sql> <!--然后在select标签中,写查询语句时,使用<include refid="片段id">标签引入sql片段--> <select id="getEmpListByMoreT" resultType="Emp"> select <include refid="empcolumns"></include> from t_emp </select>MyBatis的缓存MyBatis的一级缓存(默认开启的)一级缓存是SqlSession级别的,通过同一个SqlSession查询的数据会被缓存,下次查询相同的数据,就会从缓存中直接获取,不会从数据库重新访问使一级缓存失效的四种情况:|1)不同的SqlSession对应不同的一级缓存2)同一个SqlSession但是查询条件不同3)同一个SqlSession两次查询期间执行了任何一次增删改操作4)同一个SqlSession两次查询期间手动清空了缓存@Test public void testGetEmpById(){ SqlSession sqlSession1 = SqlSessionUtil.getSqlSession(); CacheMapper mapper1 = sqlSession1.getMapper(CacheMapper.class); Emp emp1 = mapper1.getEmpById(1); System.out.println(emp1); Emp emp2 = mapper1.getEmpById(1); System.out.println(emp2); SqlSession sqlSession2 = SqlSessionUtil.getSqlSession(); CacheMapper mapper2 = sqlSession2.getMapper(CacheMapper.class); Emp emp3 = mapper2.getEmpById(1); System.out.println(emp3); }MyBatis的二级缓存二级缓存是SqlSessionFactory级别,通过同一个SqlSessionFactory创建的SqlSession查询的结果会被缓存;此后若再次执行相同的查询语句,结果就会从缓存中获取二级缓存开启的条件:a>在核心配置文件中,设置全局配置属性cacheEnabled="true",默认为true,不需要设置b>在映射文件中设置标签<cache/>c>二级缓存必须在SqlSession关闭或提交之后有效d>查询的数据所转换的实体类类型必须实现序列化的接口使二级缓存失效的情况:两次查询之间执行了任意的增剧改,会使一级和二级缓存同时失效
-
-
本地项目上传到”码云“ 登录"码云" 登录或注册码云,进入主页后点击+号新建仓库,如下图为避免error: failed to push some refsto‘远程仓库地址’的错误不要勾选“使用Readme文件初始化这个仓库”根据向导,可直接点击立即创建即可.使用git应用 未安装git的可参考此文章.命令行模式下,进行要上传到git的目录下:初始化本地仓库git命令:git init上传他人拷贝给自己的项目时,拷贝过来的文件夹中如果有.git目录(注意此文件夹是隐藏文件夹)使用命令关联远端仓库git remote add origin 远端仓库地址查看当前配置信息git config --list 使用git status命令查看仓库文件状态-s 选项——精简输出具体参考第一列字符表示版本库与暂存区之间的比较状态。第二列字符表示暂存区与工作区之间的比较状态。' ' (空格)表示文件未发生更改M 表示文件发生改动。A 表示新增文件。D 表示删除文件。R 表示重命名。C 表示复制。U 表示更新但未合并。? 表示未跟踪文件。! 表示忽略文件。未跟踪和忽略文件会显示相同的两列,如 ??。先将修改过的文件添加到暂存区域,执行添加指令git add .再将暂存区域的文件,提交至本地仓库,执行提交指令git commit -m"commit msg"最后将本地仓库推送至远端仓库,执行推送指令git push origin master注意:如果用户信息输入有误,会提示 remote: Invalid username or password.再次执行推送指令,即可重新填写用户信息。了解:当本地仓库与远程仓库不一致时,推送并合并分支git pull --rebase origin mastergit pull origin master【Git】git pull origin master与git pull --rebase origin master的区别:git pull=git fetch + git mergegit pull --rebase=git fetch+git rebasegit fetch : 从远程分支拉取代码,可以得到远程分支上最新的代码。所以git pull origin master与git pull --rebase origin master的区别主要是在远程与本地代码的合并上面了。对比可看出:git merge多出了一个新的节点G,会将远端master的代码和test本地的代码在这个G节点合并,之前的提交会分开去显示。git --rebase会将两个分支融合成一个线性的提交,不会形成新的节点。rebase好处想要更好的提交树,使用rebase操作会更好一点。这样可以线性的看到每一次提交,并且没有增加提交节点。merge 操作遇到冲突的时候,当前merge不能继续进行下去。手动修改冲突内容后,add 修改,commit 就可以了。而rebase 操作的话,会中断rebase,同时会提示去解决冲突。解决冲突后,将修改add后执行git rebase –continue继续操作,或者git rebase –skip忽略冲突。
-
IBM MQ使用,传递消息 参考连接Jquery发送ajax请求get $.get("[后台请求地址]",{},[回调方法]function(data[返回的数据data]){ //业务处理。。。 }); $.get("category/findAll",{},function(data){} var lis = '首页'; for(var i = 0; i < data.length; i++) { //动态拼接 var li = '+ data[i].cname +'; lis += li; } //拼接尾部 lis += '收藏' //将lis字符串输出到标签中 $(#category).html(lis); );
-
Spring集成web环境 SpringMVC Spring提供获取应用上下文的工具1、分析: Spring提供了一个监听器ContextLoaderListener,上面的分析不用手动实现,该监听器内部加载Spring配置文件,创建应用上下文对象,并存储到ServletContext域中。 Spring提供了一个客户端工具WebApplicationContextUtils供使用者获得应用上下文对象。2、使用: 我们需要做两件事①在web.xml中配置ContextLoaderListener监听器(导入spring-web坐标)②使用WebApplicationContextUtils获得应用上下文对象ApplicationContext3、实例:<!--导入spring-web坐标--> <dependency> <groupId>org.springframework</groupId> <artifactId>spring-web</artifactId> <version>5.0.5.RELEASE</version> </dependency>配置web.xml<!--全局初始化参数--> <context-param> <param-value>classpath:applicationContext.xml</param-value> </context-param> <!--配置监听器--> <listener> <listener-class>org.springframework.web.context.ContextLoaderListener</1istener-class> </listener>配置算是完成了开始使用:ApplicationContext applicationContext = WebApplicationContextUtils.getWebApplicationContext(servletContext); Object obj = applicationContext.getBean ("id"); SpringMVC 统一管理处理Servlet1、分析: SpringMVC通过DispatcherServlet全局的Servlet称之为前端控制器,根据请求资源地址然后映射到具体的Controller。 视图和模型(ModelAndView),每个Controller中的每个方法根据需求进行返回,可以只返回文字信息,可以返回视图模型信息。①用户发送请求至前端控制器DispatcherServlet。②DispatcherServlet收到请求调用HandlerMapping处理器映射器。③处理器映射器找到具体的处理器(可以根据xml配置、注解进行查找),生成处理器对象及处理器拦截器(如果有则生成)一并返回给DispatcherServlet。④DispatcherServlet调用HandlerAdapter处理器适配器。⑤HandlerAdapter经过适配调用具体的处理器(Controller,也叫后端控制器)。⑥Controller执行完成返回ModelAndView。⑦HandlerAdapter将controller执行结果ModelAndView返回给DispatcherServlet。⑧DispatcherServlet将ModelAndView传给ViewReslover视图解析器。⑨ViewReslover解析后返回具体View。⑩DispatcherServlet根据View进行渲染视图(即将模型数据填充至视图中)。DispatcherServlet响应用户。2、使用:①导入SpringMVC相关坐标②web.xml配置SpringMVC核心控制器DispathcerServlet③配置SpringMVC核心文件 spring-mvc.xml④创建Controller类和视图页面⑤使用注解配置Controller类中业务方法的映射地址⑥客户端发起请求测试关于content-type类型Content-Type(内容类型)一般是指网页中存在的 Content-Type,用于定义网络文件的类型和网页的编码,决定浏览器将以什么形式、什么编码读取这个文件。该字符串通常被格式化为类型/子类型,其中类型是常规内容范畴而子类为特定内容类型。有关支持内容类型的完整列表,请参阅 Web 浏览器文档或当前的 HTTP 规格说明。ContentType属性指定响应的 HTTP内容类型。如果未指定 ContentType,默认为TEXT/HTML。SpringMVC的视图控制器在请求只需要跳转页面时,可以在配置文件中(spring mvc配置文件中)只需要通过一个标签配置,即可处理请求路径映射地址,不必在编写Controller处理方法配置标签如下:<!-- 若设置视图控制器,则只有视图控制器所设置的请求会被处理,其他的请求将全部404 此时必须在配置一个标签:<mvc:annotation-driven/> 开启mvc的注解驱动 --> <mvc:annotation-driven/> <mvc:view-controller path="/" view-name="index"></mvc:view-controller> <!--请求根路径/时,直接跳转的index页面-->
-
Redis redis的5种数据类型:string 字符串(可以为整形、浮点型和字符串,统称为元素)hash hash散列值(hash的key必须是唯一的)list 列表(实现队列,元素不唯一,先入先出原则)set 集合(各不相同的元素)sort set 有序集合string类型的常用命令:添加:set获取:get自加:incr自减:decr加: incrby减: decrbylist类型支持的常用命令:lpush:从左边推入lpop:从右边弹出rpush:从右变推入rpop:从右边弹出llen:查看某个list数据类型的长度set类型支持的常用命令:sadd:添加数据scard:查看set数据中存在的元素个数sismember:判断set数据中是否存在某个元素srem:删除某个set数据中的元素hash数据类型支持的常用命令:hset:添加hash数据hget:获取hash数据hmget:获取多个hash数据sort set和hash很相似,也是映射形式的存储:zadd:添加zcard:查询zrange:数据排序Redis的持久化redis持久化机制: 1、RDB:默认方式,不需要进行配置,默认就使用这种机制 在一定的间隔时间中,检测key的变化情况,然后持久化数据 redis安装目录下的配置文件:redis.windows.conf #900秒(15min)之后如果有一个Key发生改变就进行一次持久化 save 900 1 #300秒(5min)之后如果有10个Key发生改变就进行一次持久化 save 300 10 #60秒(1min)之后如果有10000个Key发生改变就进行一次持久化 save 60 10000 2、AOF:日志记录的方式,可以记录每一条命令的操作。可以每一次命令操作后,持久化数据使用配置的启动方式:命令行 redis-server.exe redis.windows.confredis缓存操作eg:缓存一些数据库中不宜发生改变的数据,如省份信息;将数据库中的省份信息以JSON字符串的形式保持在缓存中,每次查询时先查缓存,没有再去查询数据库 注意点:要保证redis数据与数据库的一直性,对数据库中的省份信息进行增删改操作时,要更新缓存。
-
javax.servlet.Filter与动态代理 Java过滤器 Fileter快速入门:1、定义一个类,实现**javax.servlet.Filter**接口 2、重写其3个方法,init(); doFilter(); destroy(); 3、配置拦截资源: 通过web.xml配置 注解配置 @WebFilter("urlPatterns") web.xml<?xml version="1.0" encoding="UTF-8"?> <web-app xmlns="http://xmlns.jcp.org/xml/ns/javaee" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/javaee http://xmlns.jcp.org/xml/ns/javaee/web-app_3_1.xsd" version="3.1"> <filter> <filter-name>demo1</filter-name> <filter-class>cn.itcast.web.filter.FilterDemo1</filter-class> </filter> <filter-mapping> <filter-name>demo1</filter-name> <!-- 拦截路径 --> <url-pattern>/*</url-pattern> </filter-mapping> </web-app>Filter实现代码public class FilterDemo implements Filter{ @Override public void init(FilterConfig filterConfig) throws ServletException { } @Override public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException { System.out.println("filterDemo1被执行了...."); //放行 filterChain.doFilter(servletRequest,servletResponse); } @Override public void destroy() {} }过来器生命周期1、init()方法,会在Filter对象创建时执行一次。一般可以用来加载资源2、doFilter()方法,会执行多次,符合拦截规则的请求,在请求到资源前都会执行该方法,filterChain.doFilter(servletRequest,servletResponse)放行,拿到资源后,即进行响应时会走放行后的代码3、destroy()方法,会在Filter对象被正常消耗时会执行一次。过滤器链(配置多个过滤器) * 执行顺序:如果有两个过滤器:过滤器1和过滤器2 1. 过滤器1 2. 过滤器2 3. 资源执行 4. 过滤器2 5. 过滤器1 * 过滤器先后顺序问题: 1. 注解配置:按照类名的字符串比较规则比较,值小的先执行 * 如: AFilter 和 BFilter,AFilter就先执行了。 2. web.xml配置: <filter-mapping>谁定义在上边,谁先执行 使用动态代理增强Filter过滤器中的doFilter(servletRequest,servletResponse)方法的servletRequest对象的getParameter()方法动态代理 * 概念: 1. 真实对象:被代理的对象 2. 代理对象: 3. 代理模式:代理对象代理真实对象,达到增强真实对象功能的目的 * 实现方式: 1. 静态代理:有一个类文件描述代理模式 2. 动态代理:在内存中形成代理类 * 实现步骤: 1. 代理对象和真实对象实现相同的接口 2. 代理对象 = Proxy.newProxyInstance(); 3. 使用代理对象调用方法。 4. 增强方法 * 增强方式: 1. 增强参数列表 2. 增强返回值类型 3. 增强方法体执行逻辑 @Override public void doFilter(ServletRequest servletRequest,ServletResponse servletResponse,FilterChain filterChain) throws IOException, ServletException { //1、创建代理对象,增强getParameter()方法 ServletRequest request_proxy = (ServletRequest)Proxy.newProxyInstance(servletRequest.getClass().getClassLoader(), servletRequest.getClass().getInterfaces(), new InvokeHandler(){ @Override public Object invoke(Object proxy, Method method, Object[] args) throws Throwable { //要增强getParameter(),所以进行个判断 if("getParameter".equals(method.getName())){ //增强返回值,对request对象值请求参数中的值进行个修改 String parameter = (String)method.invoke(servletRequest,args); //进行修改然后返回 return parameter.replace("#",""); }else { return method.invoke(servletRequest,args); } } }); //2、放行 filterChain.doFilter(); }
-
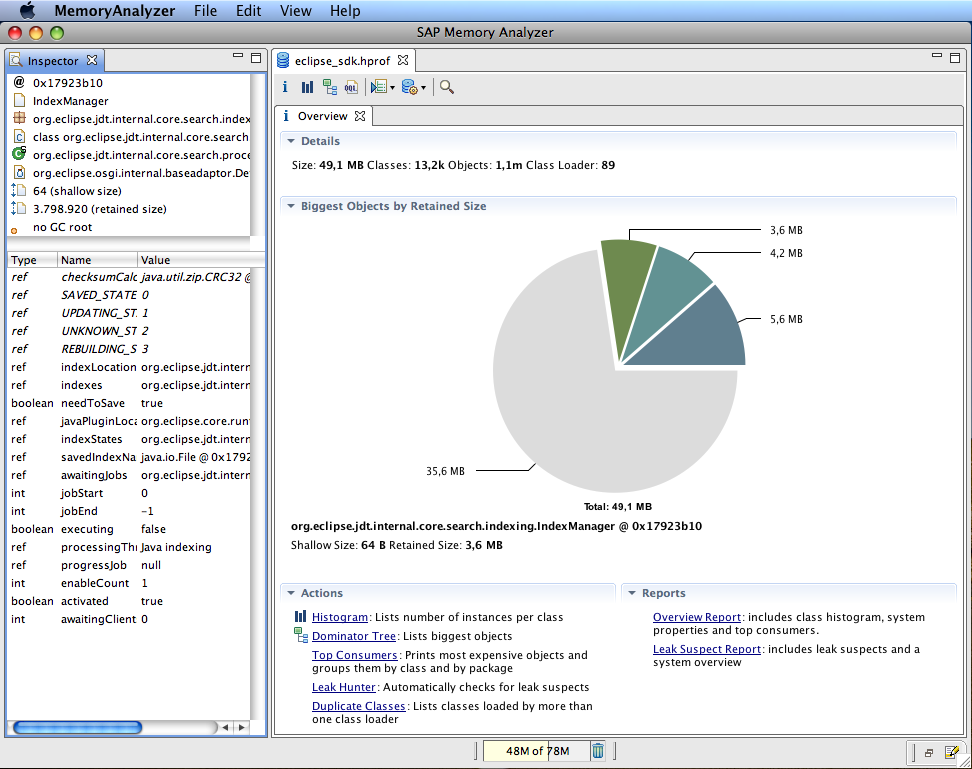
java.lang.String的substring、split方法引起的内存问题 项目运行遇到了OutOfMemoryError异常.内存溢出?觉得是不是MaxPermSize设置小了,又给了1个G的大小,试下还是不行,然后使用Java heap分析工具,找出内存占用超出预期的嫌疑对象dump heapHeap Dump也叫堆转储文件,是一个Java进程在某个时间点上的内存快照。Heap Dump是有着多种类型的。不过总体上heap dump在触发快照的时候都保存了java对象和类的信息。通常在写heap dump文件前会触发一次FullGC,所以heap dump文件中保存的是FullGC后留下的对象信息。关于Heap Dump使用jconsole获取dump heap:建立连接后,选择页签MBean,执行com.sun.management. HotSpotDiagnostic下的操作dumpHeap。第一个参数p0是要获取的dump文件的完整路径名,记得文件要以.hprof作为扩展名(要在Memory AnalysisPerspective下打开扩展名必须是这个)。如果我们只想获取live的对象,第二个参数p1需要保持为true。JDK自带的jmap工具:Java代码jmap -dump:format=b,file=heap.bin <pid> format=b的含义是,dump出来的文件时二进制格式。 file-heap.bin的含义是,dump出来的文件名是heap.bin。 <pid>就是JVM的进程号。 (在linux下)先执行ps aux | grep java,找到JVM的pid;然后再执行jmap -dump:format=b,file=heap.bin <pid>,得到heap dump文件。analyze heap将二进制的heap dump文件解析成human-readable的信息,自然是需要专业工具的帮助,Memory Analyzer Memory Analyzer,简称MAT,是Eclipse基金会的开源项目,由SAP和IBM捐助。巨头公司出品的软件还是很中用的,MAT可以分析包含数亿级对 象的heap、快速计算每个对象占用的内存大小、对象之间的引用关系、自动检测内存泄露的嫌疑对象,功能强大,而且界面友好易用。 MAT的界面基于Eclipse开发,以两种形式发布:Eclipse插件和Eclipe RCP。MAT的分析结果以图片和报表的形式提供,一目了然。{gird column="2" gap="15"}{gird-item}{/gird-item}{gird-item}{/gird-item}{/gird}最后发现到这里内存突然就爆增看到这里我就觉得是不是split()使用的有什么问题于是就上网查了一下split学习了一下。原文连接:https://blog.csdn.net/caihaijiang/article/details/7748560先用一个极端例子说明String的substring方法引起的OutOfMemoryError问题:public class TestGC { private String large = new String(new char[100000]); public String getSubString() { return this.large.substring(0,2); } public static void main(String[] args) { ArrayList<String> subStrings = new ArrayList<String>(); for (int i = 0; i <1000000; i++) { TestGC testGC = new TestGC(); subStrings.add(testGC.getSubString()); } } }:对一个很长的字符串,使用substring循环保留该字符串里面的一小部分,保存到HashMap中运行该程序,结果出现:Exception in thread "main" java.lang.OutOfMemoryError: Java heap space为什么会出现这个情况?查看一下JDK String类substring方法的源码,可以找到原因,源码如下: public String substring(int beginIndex, int endIndex) { if (beginIndex < 0) { throw new StringIndexOutOfBoundsException(beginIndex); } if (endIndex > count) { throw new StringIndexOutOfBoundsException(endIndex); } if (beginIndex > endIndex) { throw new StringIndexOutOfBoundsException(endIndex - beginIndex); } return ((beginIndex == 0) && (endIndex == count)) ? this : new String(offset + beginIndex, endIndex - beginIndex, value); }该方法最后一行,调用了String的一个私有的构造方法,如下: // Package private constructor which shares value array for speed. String(int offset, int count, char value[]) { this.value = value; this.offset = offset; this.count = count; }该方法为了避免内存拷贝,提高性能,并没有重新创建char数组,而是直接复用了原String对象的char[],通过改变偏移量和长度来标识不同的字符串内容。也就是说,substring出的来String小对象,仍然会指向原String大对象的char[],所以就导致了OutOfMemoryError问题。找到问题之后,将上面代码中,getSubString的方法修改一下,如下: public String getSubString() { return new String(this.large.substring(0,2)); }将substring的结果,重新new一个String出来。再运行该程序,则没有出现OutOfMemoryError的问题。为什么?因为此时调用的是String类的public的构造方法,该方法源码如下: public String(String original) { int size = original.count; char[] originalValue = original.value; char[] v; if (originalValue.length > size) { // The array representing the String is bigger than the new // String itself. Perhaps this constructor is being called // in order to trim the baggage, so make a copy of the array. int off = original.offset; v = Arrays.copyOfRange(originalValue, off, off+size); } else { // The array representing the String is the same // size as the String, so no point in making a copy. v = originalValue; } this.offset = 0; this.count = size; this.value = v; }从代码可以看出,在String对象中value的length大于count的情况下,会重新创建一个char[],并进行内存拷贝。除了substring方法之后,String的split方法,也存在同样的问题,split的源码如下: public String[] split(String regex, int limit) { return Pattern.compile(regex).split(this, limit); }可以看出,String的split方法通过Pattern的split方法来实现,Pattern的split方法源码如下:public String[] split(CharSequence input, int limit) { int index = 0; boolean matchLimited = limit > 0; ArrayList<String> matchList = new ArrayList<String>(); Matcher m = matcher(input); // Add segments before each match found while(m.find()) { if (!matchLimited || matchList.size() < limit - 1) { String match = input.subSequence(index, m.start()).toString(); matchList.add(match); index = m.end(); } else if (matchList.size() == limit - 1) { // last one String match = input.subSequence(index, input.length()).toString(); matchList.add(match); index = m.end(); } } // If no match was found, return this if (index == 0) return new String[] {input.toString()}; // Add remaining segment if (!matchLimited || matchList.size() < limit) matchList.add(input.subSequence(index, input.length()).toString()); // Construct result int resultSize = matchList.size(); if (limit == 0) while (resultSize > 0 && matchList.get(resultSize-1).equals("")) resultSize--; String[] result = new String[resultSize]; return matchList.subList(0, resultSize).toArray(result); }方法中的第9行: Stirng match = input.subSequence(intdex, m.start()).toString();调用了String类的subSequence方法,该方法源码如下: public CharSequence subSequence(int beginIndex, int endIndex) { return this.substring(beginIndex, endIndex); }通过代码可以看出,最终调用的是String类的substring方法,因此存在同样的问题。split出来的小对象,直接使用原String对象的char[]。看了一下StringBuilder和StringBuffer的substring方法,则不存在这样的问题。其源码如下: public String substring(int start, int end) { if (start < 0) throw new StringIndexOutOfBoundsException(start); if (end > count) throw new StringIndexOutOfBoundsException(end); if (start > end) throw new StringIndexOutOfBoundsException(end - start); return new String(value, start, end - start); }最后一行,调用了String类的public构造方法,方法源码如下: public String(char value[], int offset, int count) { if (offset < 0) { throw new StringIndexOutOfBoundsException(offset); } if (count < 0) { throw new StringIndexOutOfBoundsException(count); } // Note: offset or count might be near -1>>>1. if (offset > value.length - count) { throw new StringIndexOutOfBoundsException(offset + count); } this.offset = 0; this.count = count; this.value = Arrays.copyOfRange(value, offset, offset+count); }方法不是直接使用原String对象的char[],而是重新进行了内存拷贝。